Solving AWS Lambda Timeout Issues for LLM Workloads Using SQS and Serverless Architecture

Running Large Language Models (LLMs) in a serverless environment sounds straightforward at first. AWS Lambda offers scalability, low operational overhead, and seamless integration with Node.js applications. Combined with frameworks like LangChain, it becomes easy to build AI-powered workflows quickly.
However, when LLM inference enters the picture, many teams encounter a critical issue: AWS Lambda timeouts. This problem is not caused by poor configuration or inefficient code. It is caused by a fundamental mismatch between synchronous serverless APIs and long-running AI workloads.
This article walks through a practical, production-ready way to solve this issue using AWS SQS, while keeping your architecture fully serverless.
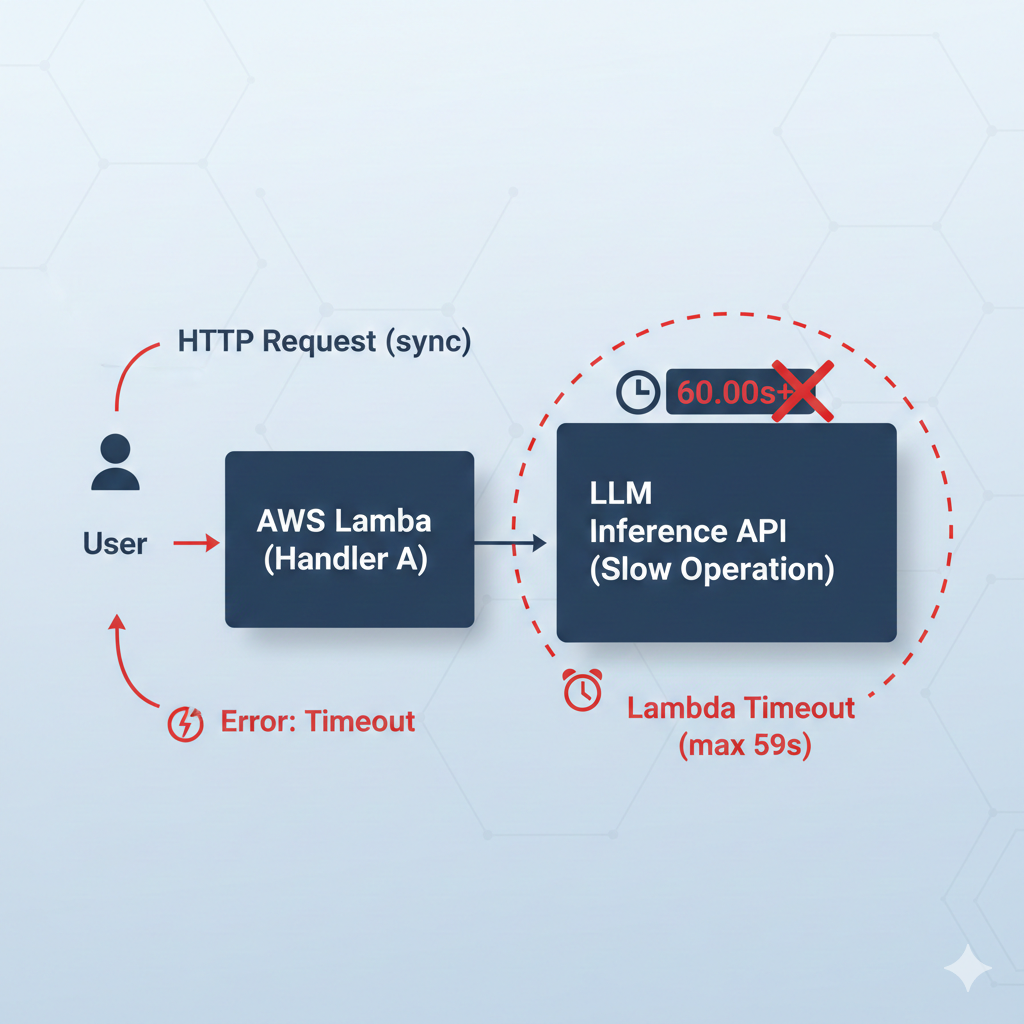
Understanding Why AWS Lambda Timeouts Happen with LLMs
AWS Lambda functions are designed to execute short-lived tasks. Even though the timeout limit can be increased, LLM inference time is unpredictable. Factors such as prompt size, token count, model latency, and multi-step LangChain chains all contribute to variable execution duration.
When LLM calls are placed directly inside API-triggered Lambda functions, the API Gateway must wait until the Lambda finishes execution. If the model takes longer than expected, the request fails, regardless of whether the model eventually returns a valid response.
This architectural mismatch becomes more visible as traffic increases and prompts become more complex.
Why Increasing Lambda Limits Is Not a Real Solution
A common reaction is to increase the Lambda timeout or memory allocation. While this may temporarily reduce failures, it does not solve the root problem. LLM execution time cannot be reliably predicted, and API reliability should not depend on inference duration.
From an engineering perspective, this leads to brittle systems. From a product perspective, users experience random failures that are difficult to diagnose or reproduce.
The Correct Way to Think About LLM Execution in Serverless Systems
The correct approach is to treat LLM execution as a background task, not a synchronous API operation. APIs should be fast, predictable, and resilient. LLM inference should be decoupled from the request-response lifecycle.
This is where AWS SQS (Simple Queue Service) becomes essential.
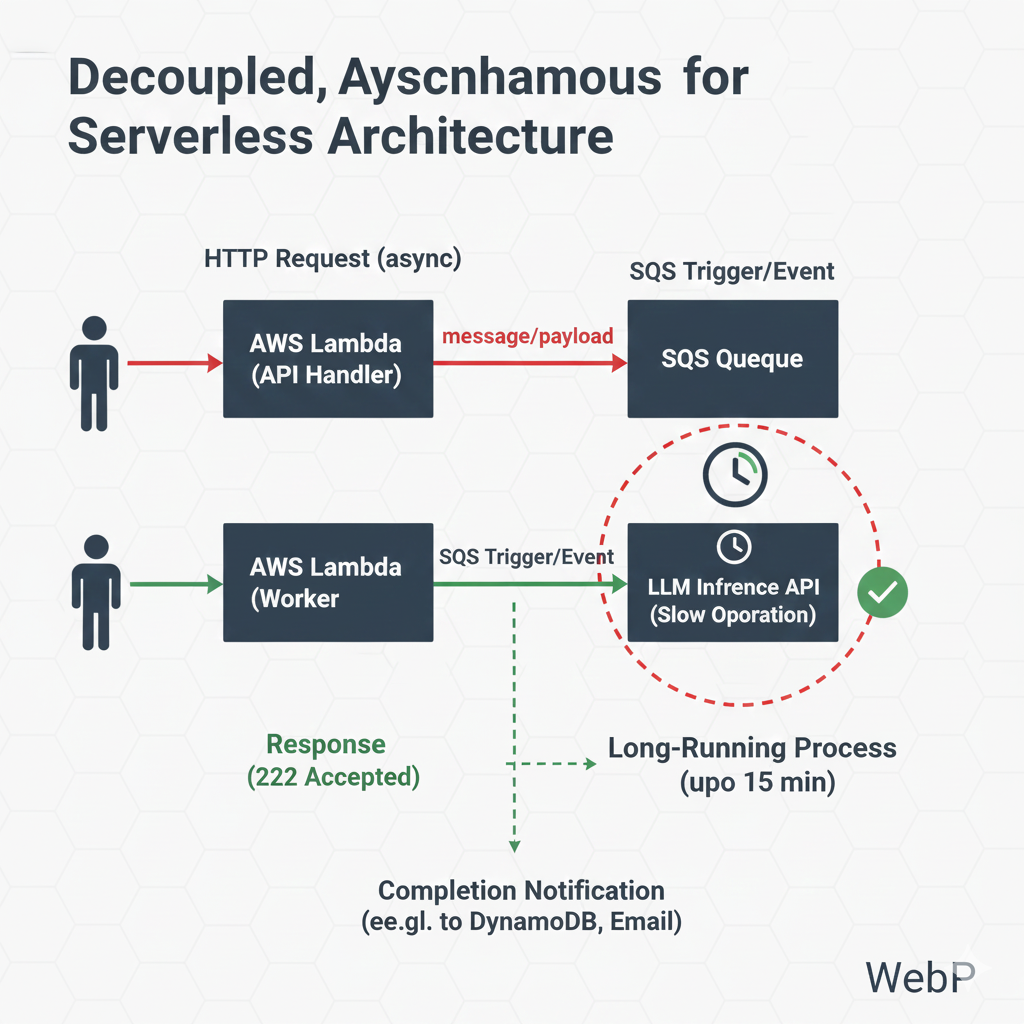
Decoupling LLM Execution Using AWS SQS
Instead of invoking the model directly from the API Lambda, introduce SQS as an asynchronous execution layer.
The API Lambda becomes responsible only for validating the request and placing a message onto a queue. A separate Lambda function, triggered by SQS, performs the LangChain and LLM execution independently.
This simple separation removes all timeout pressure from the API layer.
High-Level Flow of the Architecture
A request now follows a clear and reliable path. The client calls the API Gateway, which triggers an API Lambda. That Lambda pushes a message to SQS and immediately returns a success response. Separately, an SQS-triggered Lambda consumes the message and executes the LLM workflow.
This design allows the API to remain responsive while the AI workload runs safely in the background.
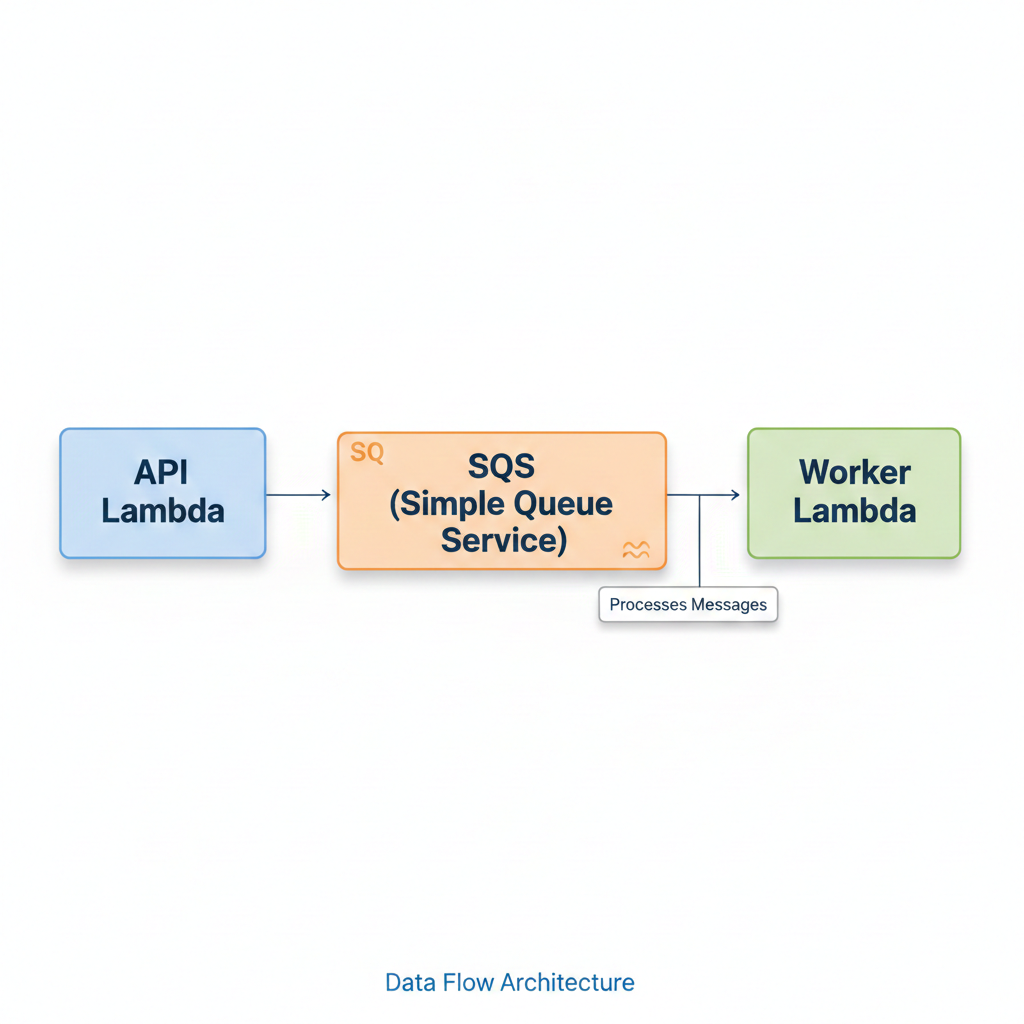
Serverless Configuration for SQS-Triggered Lambdas
Using the Serverless Framework, configuring an SQS-triggered Lambda follows a standard pattern defined in official AWS documentation.
functions:
apiHandler:
handler: src/api.handler
events:
- http:
path: invoke
method: post
llmWorker:
handler: src/worker.handler
events:
- sqs:
arn:
Fn::GetAtt:
- LLMQueue
- Arn
resources:
Resources:
LLMQueue:
Type: AWS::SQS::Queue
Properties:
VisibilityTimeout: 300
The visibility timeout should always be aligned with the expected LLM execution time to prevent duplicate processing.
Sending Jobs to SQS from the API Lambda
The API Lambda publishes messages to SQS using the AWS SDK v3. This follows the official AWS Node.js pattern.
import { SQSClient, SendMessageCommand } from "@aws-sdk/client-sqs";
const sqs = new SQSClient({ region: process.env.AWS_REGION });
export const handler = async (event) => {
const body = JSON.parse(event.body);
await sqs.send(
new SendMessageCommand({
QueueUrl: process.env.QUEUE_URL,
MessageBody: JSON.stringify(body),
})
);
return {
statusCode: 202,
body: JSON.stringify({ message: "Request accepted for processing" }),
};
};
The API now responds immediately, regardless of how long inference takes.
Executing LangChain Inside the Worker Lambda
The worker Lambda processes messages from SQS and invokes the LLM using LangChain’s official Node.js interface.
import { ChatOpenAI } from "langchain/chat_models/openai";
import { HumanMessage } from "langchain/schema";
export const handler = async (event) => {
for (const record of event.Records) {
const payload = JSON.parse(record.body);
const model = new ChatOpenAI({
temperature: 0,
});
const response = await model.call([
new HumanMessage(payload.prompt),
]);
console.log(response.content);
}
};
Because this Lambda is no longer tied to an API request, it can safely run close to the maximum timeout limit
Retry and Error Handling with SQS
One of the strongest advantages of this architecture is built-in reliability. SQS automatically retries message processing if the worker Lambda fails. By configuring a Dead Letter Queue (DLQ), failed messages can be isolated and inspected without impacting the rest of the system.
There is no need to write custom retry logic inside Lambda code.
This approach significantly improves system stability and observability.
Performance Improvements Observed
After implementing this pattern, API timeout errors dropped to zero. API response times became consistently fast, as they no longer waited for LLM execution. Under load, the system scaled predictably, and costs stabilized due to reduced retries and failures.
From a business perspective, this translated into better user experience. From an engineering perspective, it resulted in a cleaner, more maintainable architecture.
When This Pattern Should Be Used
This approach is ideal when running LLMs in AWS Lambda, especially when inference time is unpredictable or when LangChain workflows involve multiple steps. It is particularly well-suited for production-grade AI systems where reliability matters more than synchronous execution.
Final Thoughts
LLMs introduce execution characteristics that traditional serverless APIs are not designed to handle. By decoupling inference using AWS SQS, it is possible to keep your system fully serverless while eliminating timeout-related failures.
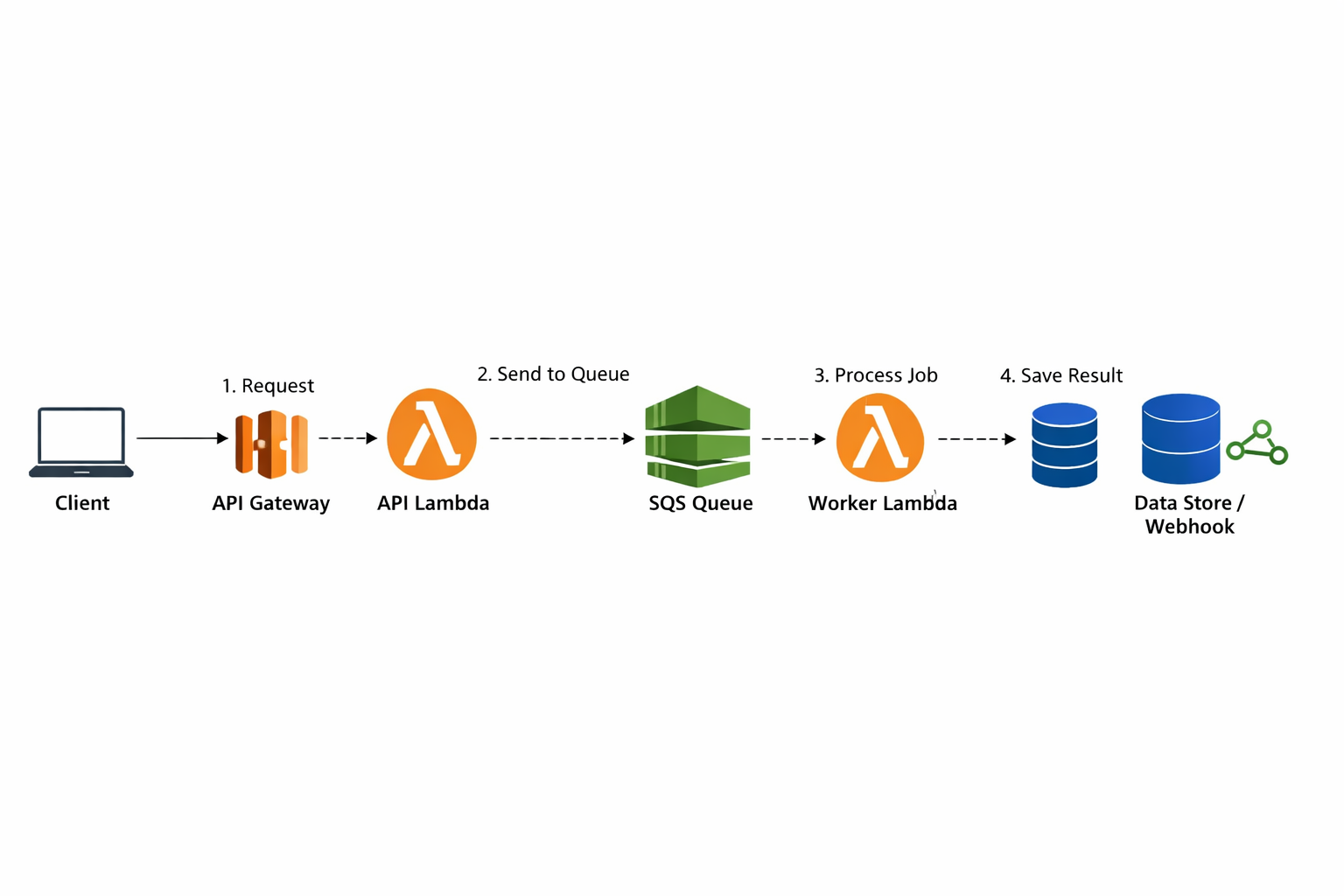
This pattern has become a foundational design for scalable, reliable AI systems built on AWS.